

12 min read
Why Multilingual AI Data Quality Is Hard to Get Right
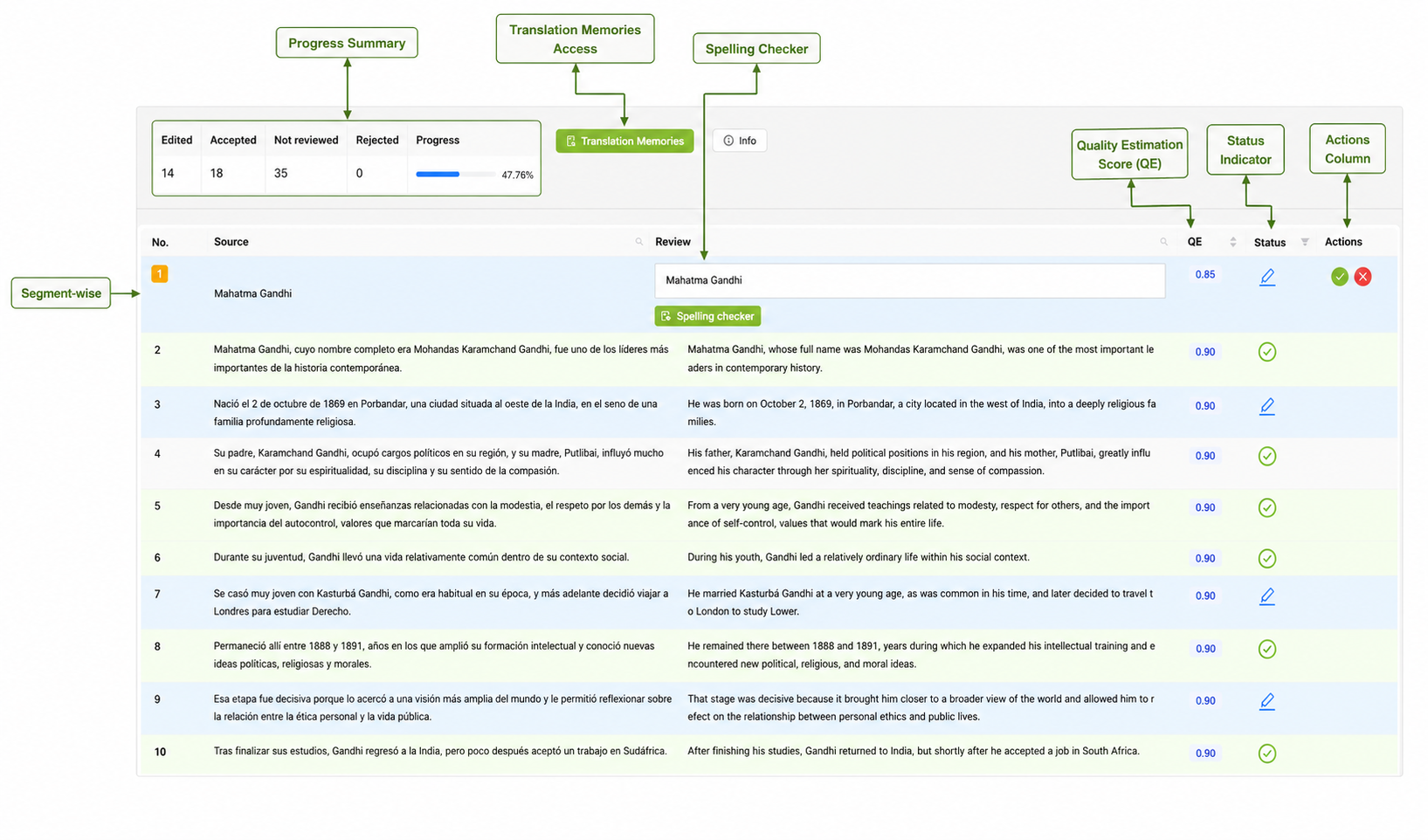
Multilingual AI data quality is the degree to which training, grounding, evaluation, and alignment datasets represent...
Pangeanic approaches parallel corpora creation and processing as an infrastructural discipline for multilingual AI. From multilingual data sourcing to precise alignment, linguistic validation, terminology control, and data governance, each layer is designed to reduce noise and preserve semantic correspondence across languages.
The result is not simply bilingual text. It is structured multilingual intelligence ready to support machine translation, retrieval across languages, language model adaptation, evaluation workflows, and production AI systems under real deployment conditions.


Trusted by global technology leaders for mission-critical multilingual data operations at scale
Pangeanic created over 50 million aligned segments across more than 20 languages, with a strong focus on low-resource linguistic environments. The project combined scale, linguistic precision and accelerated execution timelines to support multilingual AI model training at production level for millions of users

For a Top-10 NASDAQ company, across 27 languages and multiple operational domains, Pangeanic developed 45+ million segments tailored for multilingual AI and translation model development. The contribution strengthened linguistic consistency for millions of users of this critical translation system
Pangeanic generated more than 10 million aligned segments across two languages, demonstrating high linguistic depth and operational rigor within narrowly defined language pairs. The project reflected the company’s capacity to sustain quality and consistency at scale across all steps of parallel corpora creation.
Pangeanic’s data and language operations are supported by certified management systems for quality, translation services, information security, medical device quality processes and human review of machine translation output. These standards help ensure that PECAT workflows remain consistent, secure, auditable and reliable in production environments.





Sources: ISO information on quality management, translation services, information security, medical device quality management and full human review of machine translation output. ISO 9001, ISO 17100, ISO IEC 27001, ISO 13485, ISO 18587.