

18 min read
How Human-Validated Benchmark Data Improves Coding Agents, Q&A Systems and Sovereign AI Models
AI DATA OPERATIONS · MODEL EVALUATION · HUMAN ALIGNMENT How Human-Validated Benchmark Data Improves Coding Agents, Q&A...
At Pangeanic, speech dataset creation and processing are approached as an infrastructural discipline for audio native AI. From multilingual speech collection to high fidelity transcription, speaker annotation, acoustic labeling, and quality review, each layer is designed to reduce noise and improve the reliability of training pipelines.
The result is not simply audio data. It is structured acoustic intelligence ready to support speech recognition, speech synthesis, speaker diarization, conversational AI, voice agents, and multimodal language models under real deployment conditions.

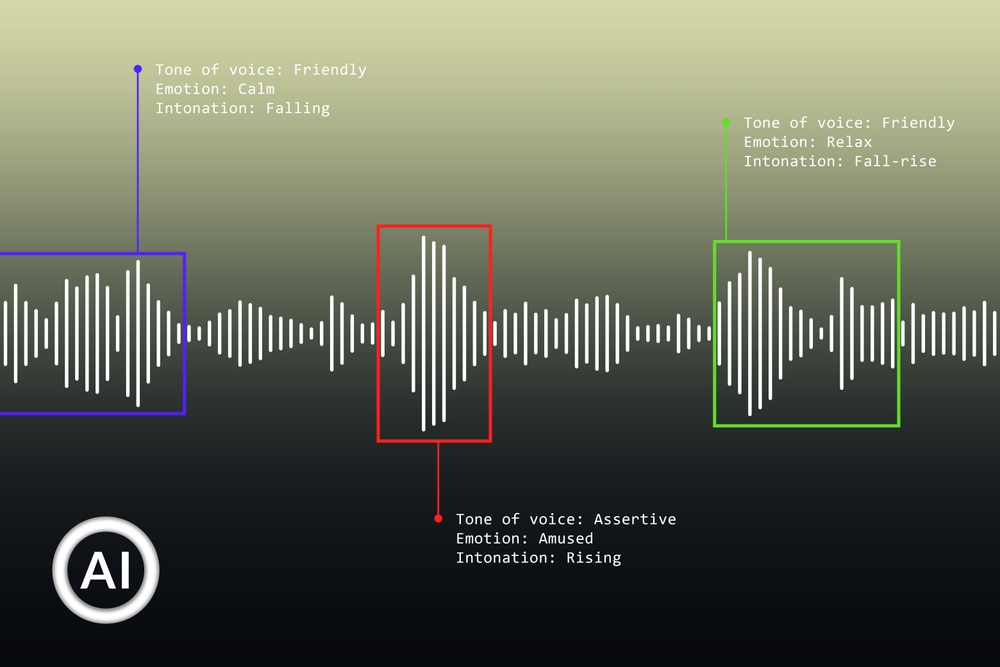
Pangeanic’s speech data pipelines have been deployed in environments where transcription accuracy, multilingual consistency, accessibility, and regulatory control are structurally required. These use cases show how speech data collection, transcription, speaker processing, human review, metadata enrichment, and privacy controls can become operational infrastructure for public institutions and AI systems.

Human reviewed transcription and subtitling workflows help preserve verbatim accuracy across Spanish and Valencian. Validation steps support institutional tone, accessibility, and searchable legislative archives.

AI supported transcription with expert linguistic validation helps process parliamentary discourse across Spanish, Catalan, Galician, and Basque while preserving legal integrity, traceability, and institutional precision.

More than 2,000 hours of multilingual audio were processed through segmentation, timestamps, transcription, speaker diarization, named entity annotation, personal data anonymization, and metadata enrichment.
Sources: Pangeanic use cases on Valencian Parliament transcription, Spanish National Parliament multilingual transcription, and comprehensive speech data processing for AI. Valencian Parliament, Spanish National Parliament, speech data processing for AI.
Pangeanic’s speech data, language, and AI data operations are supported by certified management systems for quality, translation services, information security, medical device quality processes, and human review of machine translation output. These standards help ensure that PECAT workflows for speech collection, transcription, annotation, review, and governed delivery remain consistent, secure, auditable, and reliable in production environments.





Sources: ISO information on quality management, translation services, information security, medical device quality management, and full human review of machine translation output. ISO 9001, ISO 17100, ISO IEC 27001, ISO 13485, ISO 18587.