

10 min read
AI in Oman: From National Strategy to an AI Special Zone
Oman has moved from policy statements to institutional infrastructure. The creation of an Artificial Intelligence...
PECAT is not a generic labeling tool. It is an operational layer for managing multilingual data annotation, human review and evaluation workflows in environments where quality, traceability and governance are not optional.

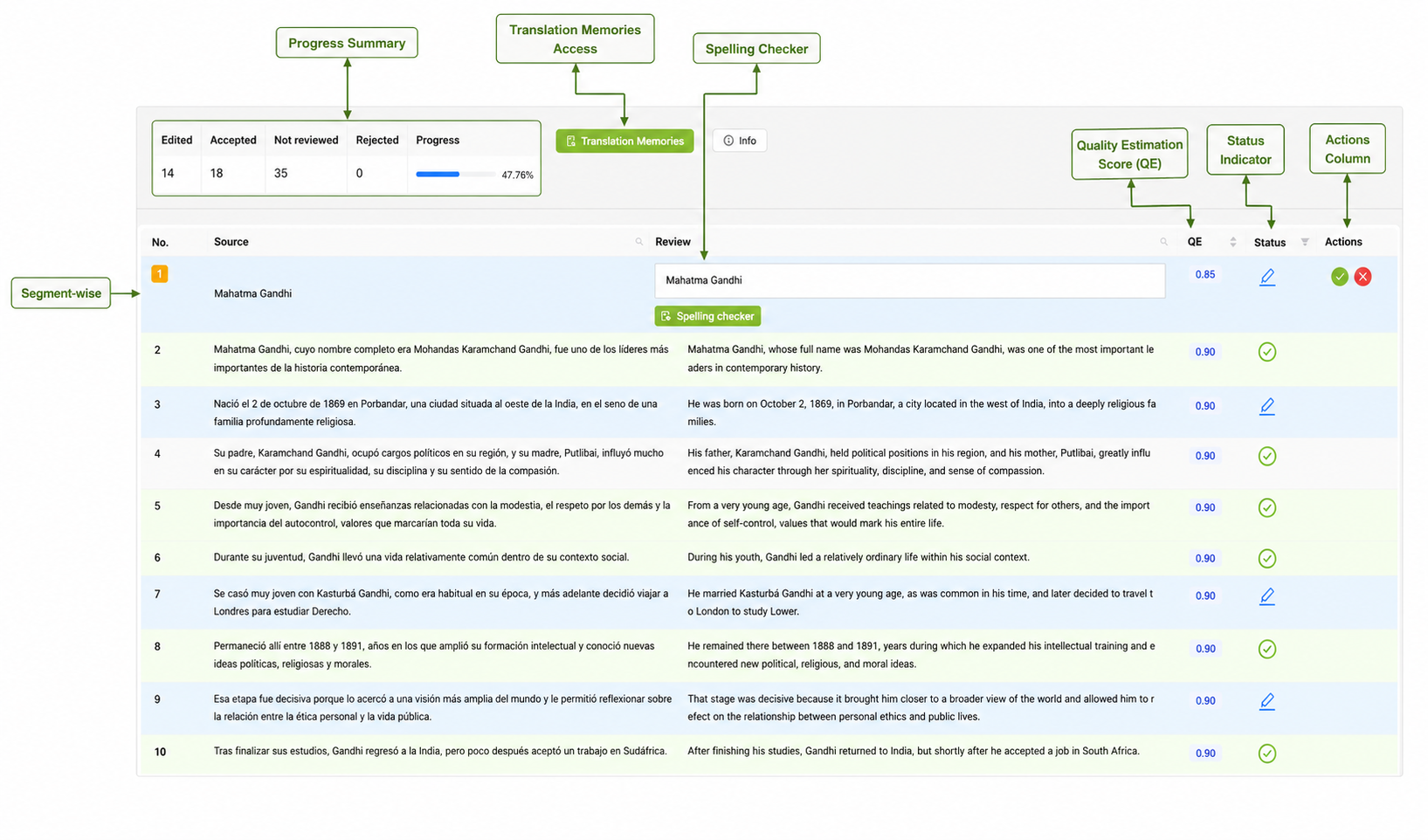
PECAT has been deployed in environments where multilingual data, human feedback and evaluation pipelines required consistency, traceability and production-grade control.

Delivered data annotation, RLHF workflows and evaluation datasets supporting large language model training and experimentation. PECAT structured human-in-the-loop quality control, ensuring consistency and rigor across multilingual datasets. The collaboration with BSC’s Language Technologies Unit contributed to ongoing work in language models, translation and NLP research.
Built a multilingual corpus of idiomatic expressions across languages and cultural contexts. The project was executed in PECAT through coordinated workflows between internal teams and external linguists. It ensured linguistic nuance, annotation consistency and scalability for downstream AI and language systems.
PECAT's proof of operational excellence that ensures annotation remains consistent, secure, and reliable in production environments.




