

14 min read
7 Criteria for Choosing Multilingual AI Training Data Services for Custom Models
Enterprise AI no longer buys annotation. Enterprise AI buys evaluation capability. Labels remain necessary, but they no...
At Pangeanic, image dataset creation and processing is approached as an infrastructural discipline: from visual data collection to annotation, labeling, OCR validation and metadata enrichment, each layer is designed to reduce entropy in computer vision and multimodal AI training pipelines.
The result is not simply data, but structured visual intelligence ready to support image recognition, object detection, OCR, multimodal LLMs and AI vision systems under real deployment conditions.

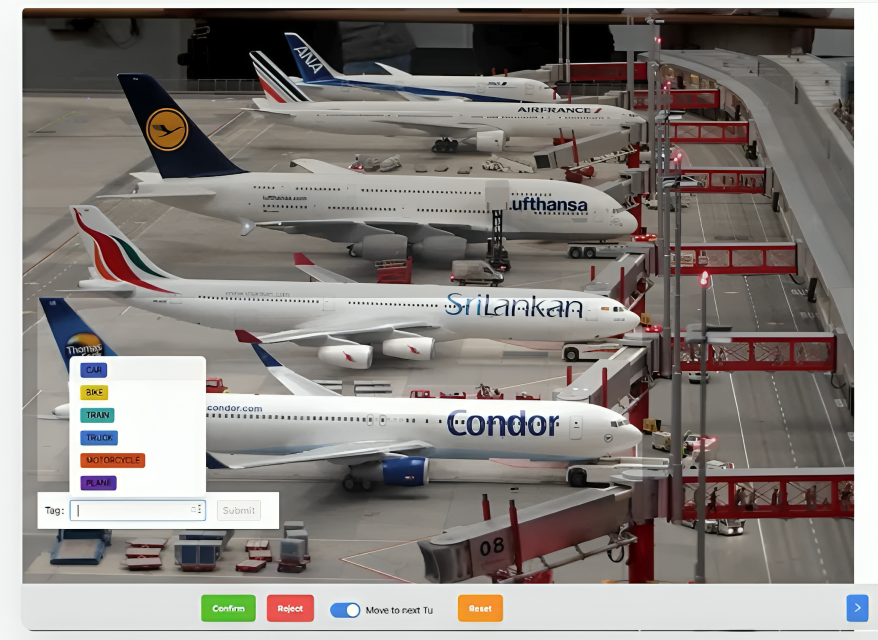
PECAT is supported by Pangeanic’s operational quality framework, helping annotation, validation and data governance remain consistent, secure and reliable in production environments.





Sources: ISO information on quality management, translation services, information security, medical device quality management, and full human review of machine translation output. ISO 9001, ISO 17100, ISO IEC 27001, ISO 13485, ISO 18587.