

Own the models that run your workflows—faster, cheaper, and auditable, without sending data to public clouds. At Pangeanic, we integrate generative AI into your corporate infrastructure, ensuring privacy, terminological precision, and absolute data sovereignty.

Run on your hardware: edge, VPC, or on‑prem

Interpretable evaluation: benchmark, regress, and certify

Pangeanic’s Small Language Model Customization Service:
-
Expert Data Curation: Natural Language Processing (NLP) was the foundation of current AI. Since 2009, we prepare, clean, and anonymize (your) data to ensure high-quality training datasets (or the opposite: reinforce named entities for better recognition).
-
Technology Independence: We are architecture-agnostic; we select the optimal open-source base model to customize based on your specific goals and requirements.
-
Advanced RAG Implementation: We connect your SLM to your live databases, ensuring that AI responses are always up-to-date and contextually accurate.
-
Security and Compliance: We apply rigorous PII (Personally Identifiable Information) masking protocols in strict compliance with GDPR and global AI security standards.
-
Flexible Deployment: We offer versatile deployment options, including on-premise servers, edge environments, or hybrid private clouds.

Don’t just take our word for it... See the specialized difference!
Generic AI is a jack-of-all-trades, but a master of none. Experience how a customized Small Language Model (SLM) outperforms standard models in your specific domain. Request a personalized demo or a Proof of Concept (POC) to witness the superior terminology, reduced latency, and absolute data privacy that Pangeanic’s expert-tuned models provide, in healthcare, in manufacturing, in law & order, open-source intelligence, news agencies, and in government applications with ECOChat, the multilingual custom chatbot for knowledge dissemination hub.
The combination of a small language model and RAG systems, in the form of public or containerized private chatbots, offers fluency in all the tasks they have been designed for, without hallucinations, referring to your data repositories and even live sources.

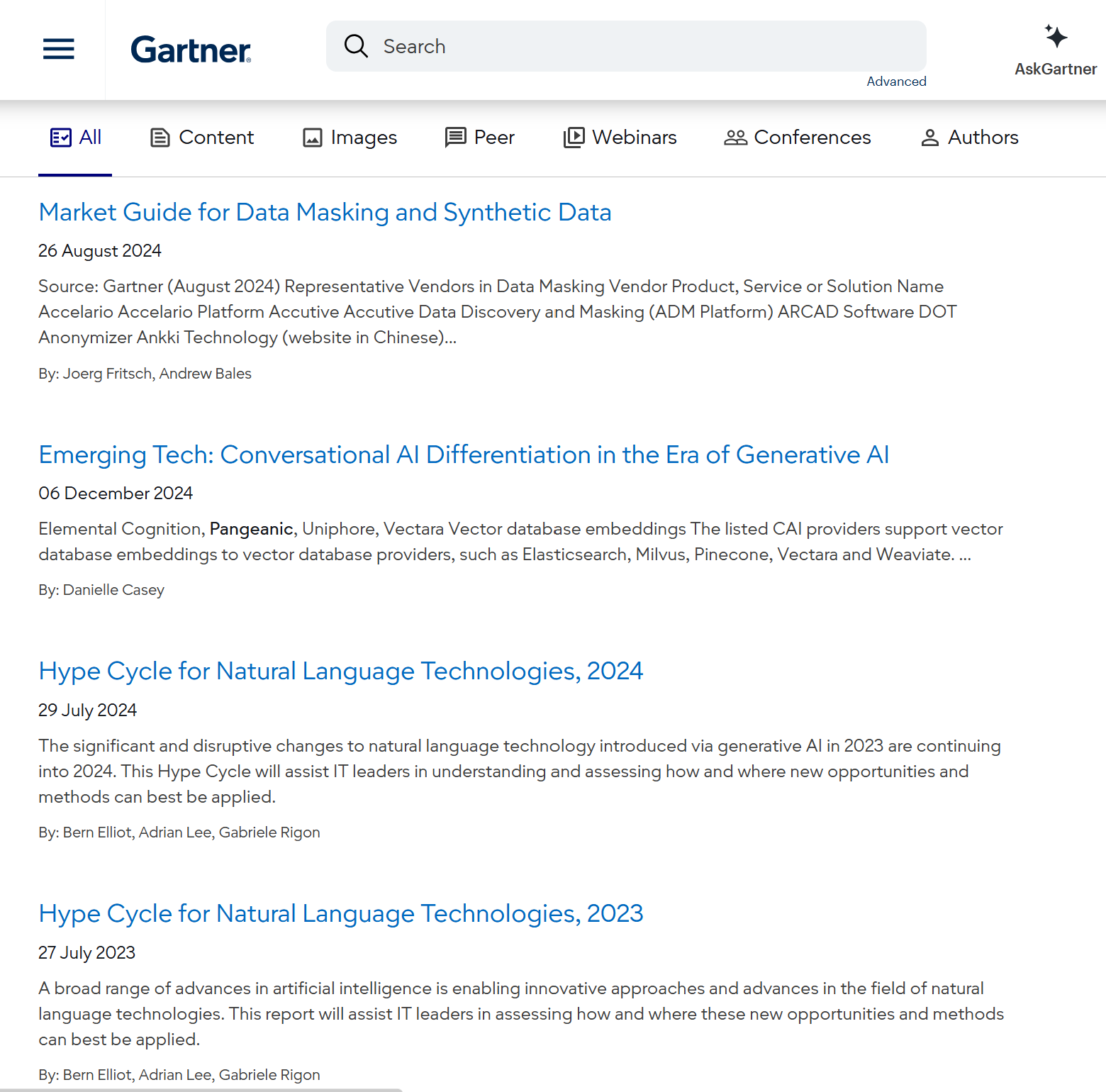
Featured in the Gartner® Hype Cycle™ for Natural Language Technologies, (2023, 2024), Vendor in Conversational AI (December 2024) and Synthetic Data & Data Masking (July 2024)
Gartner’s analysis of risks and opportunities in language technology adoption highlights Pangeanic’s leadership in the field:
- Sample Vendor Recognition: Pangeanic is recognized as a Sample Vendor for Neural Machine Translation (NMT) in the 2023 and 2024 Hype Cycle reports.
- Advanced Customization: The report highlights our specialized capability to adapt and fine-tune linguistic models to the unique, high-precision needs of our clients, from Farsi and Arabic to Russian machine translation, and to specific models with slang and drug cartel jargon.
- Strategic Foundation for SLMs: Our government- and industry-validated expertise in Neural Machine Translation customization serves as the technical cornerstone for our larger specialized Small Language Model (SLM) development.
- Representative Vendor in Gartner's Emerging Tech: Conversational AI.
.png)









Frequently Asked Questions About SLM Customization
Why SLMs over commercial LLMs for regulated workflows?
Generic LLMs are probabilistic toys for consumer chat. SLMs are engineered systems you own, audit, and certify. They are ideal when compliance failure costs millions.
Can SLMs match LLM performance on my tasks?
Yes, on bounded tasks with your data. We benchmark against fixed test suites (e.g. 95% F1 for contract redaction vs GPT‑4's 82%). Narrow scope always means predictable excellence.
How do you guarantee data sovereignty?
Zero data leaves your control. Training happens in your VPC/on‑prem. Model weights + audit logs stay yours. No backdoors to public clouds.
What's the timeline for a custom SLM?
4–8 weeks end‑to‑end: Week 1 data curation, Week 3 first model, Week 5 production deployment. Quarterly retraining thereafter.
How do SLMs integrate with my stack?
Docker/K8s containers, REST APIs, or inside the ECO platform. Feed outputs to RAG, chat UIs, or orchestration layers. Works behind ServiceNow, Jira, or custom agents.
What data do you need to start?
Your existing assets: technical manuals, support tickets, contracts, logs. We anonymize PII using ECO masking, augment with synthetic domain data, and label 1–10K quality examples. Success depends on relevance, not volume (1–2 weeks prep).
Can one SLM handle multiple languages?
Yes. Multilingual SLMs maintain domain precision across 12+ languages. For example, a legal translation 7B SLM works simultaneously in English ↔ Spanish ↔ German ↔ French. We recommend that on-device, smaller, distilled models (2B or 1.8B) perform translation between only one language pair or carry out a specific task.
How do you measure SLM success post‑deployment?
Fixed KPIs agreed at the beginning of the project: F1 score (accuracy), p95 latency (speed), compliance rate (no leaks), and cost per request. Custom dashboards + quarterly tests give your team real-time visibility without data science expertise.

Start Customizing Your Small Language Models Today
Don’t leave your AI strategy in the hands of third parties. Build a sustainable competitive advantage with proprietary models that belong exclusively to your business.

 .
.