

Manuel Herranz
CEO, Pangeanic
“Enterprises do not need more raw data. They need the right data, structured, validated, and aligned to the model behavior they want in production.”
Commission new datasets for specific domains, languages, accents, channels, or task requirements when off-the-shelf material is not enough.
Bring your own data and we will clean, normalize, relabel, enrich, and validate it so it becomes more usable for training, fine-tuning, or evaluation.
Combine proprietary assets with newly collected material, human review, metadata enrichment, and evaluation workflows to create higher-value datasets.


CEO, Pangeanic
“Enterprises do not need more raw data. They need the right data, structured, validated, and aligned to the model behavior they want in production.”

PhD, Machine Learning
“Training data quality is not a support function. It is one of the main variables behind model accuracy, robustness, and adaptation to real-world workflows.”
“For multilingual AI, dataset design matters as much as model choice. Evaluation sets, annotation consistency, and domain coverage often determine whether a system scales reliably or fails quietly.”

Many providers can label or transcribe data. Fewer understand how multilingual data affects machine translation, ASR, retrieval, evaluation, and downstream enterprise workflows.
Pangeanic stands apart because our work is rooted in language technology. We bring experience from machine translation, NLP, speech processing, model evaluation, and multilingual AI deployments.
Our teams work across the full data lifecycle: collection, annotation, quality assurance, de-identification, evaluation, and continuous improvement. That makes us particularly effective when clients need more than volume — when they need precision, consistency, and relevance to real model behavior.
We have supported language technology initiatives linked to research infrastructures, global technology environments, multilingual evaluation, and large-scale data preparation workflows where quality cannot be improvised.
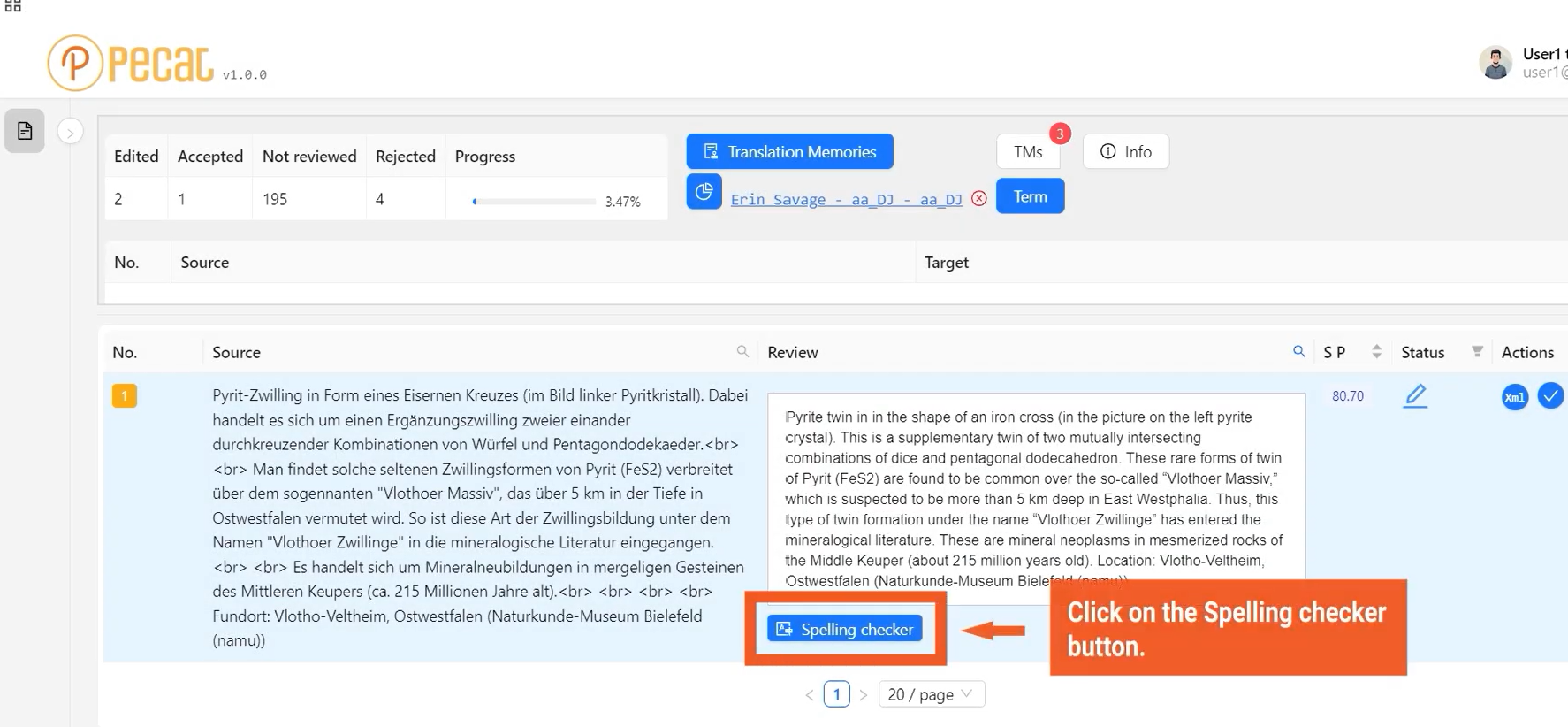
Gartner’s analysis of risks and opportunities in language technology adoption highlights Pangeanic’s leadership in the field:
.png)









Multilingual AI training data services prepare the datasets used to train, fine-tune, and evaluate AI systems across languages. These services include speech data collection, transcription, text annotation, metadata enrichment, dataset cleaning, and benchmark creation for LLMs, ASR, machine translation, and enterprise NLP.
Yes. Pangeanic can clean, normalize, enrich, relabel, validate, and restructure existing datasets so they become more useful for training, fine-tuning, or evaluation workflows.
Pangeanic works with speech, text, and selected multimodal datasets. Services include transcription, diarization, NER, sentiment and intent annotation, metadata enrichment, parallel corpora preparation, and benchmark dataset creation.
Well-designed multilingual datasets improve language coverage, domain adaptation, terminology consistency, and model reliability across markets. They help reduce bias toward high-resource languages and support better real-world performance.
Yes. Pangeanic supports evaluation-ready datasets, gold sets, benchmark creation, multilingual quality review, human adjudication, and error analysis to help teams measure and improve model performance.

 .
.