

Robust evaluation is essential to move AI systems from experimentation to reliable production. Pangeanic designs multilingual evaluation pipelines that combine human review, benchmark datasets, and domain-specific scoring criteria to assess model behavior across tasks and languages. These evaluation frameworks help AI teams detect hallucinations, measure real-world usefulness, and continuously improve model performance through structured testing and feedback loops.
">

AI Data Operations Architecture
Enterprise AI does not become reliable solely through model training. It becomes reliable when the full data and feedback lifecycle is engineered correctly.
The architecture below shows the layers that support high-performing AI systems:
-
Data collection and source preparation provide the raw material for training, retrieval, and evaluation. High-performance models require flawless tokenization and syntax parsing. Our pipeline supports advanced formatting validation for structured rationale datasets in STEM domains. By enforcing native Markdown paired with precise inline and display KaTeX/LaTeX mathematical rendering, we guarantee data packages arrive fully optimized for direct training injection.
-
Training data and SFT pipelines shape baseline model behavior and domain relevance.
-
RLHF and human evaluation align outputs with user expectations, safety requirements, and enterprise policies.
-
Benchmarking and quality assurance measure whether models actually perform well in production conditions.
-
Governance, privacy, and multilingual review ensure that AI systems can scale responsibly across markets, jurisdictions, and use cases. Safety alignments built strictly in mono-lingual environments inevitably degrade across international markets. Defend your models against cross-language safety degradation, jailbreaks, and localized compliance anomalies using targeted adversarial prompt datasets. Pangeanic’s managed human-review networks stress-test your system's guardrails with realistic, multi-turn attack simulations.
Pangeanic brings these layers together into one operational framework, helping organizations move beyond raw datasets toward AI systems that are aligned, measurable, and enterprise-ready.
Enterprises and global AI Labs need multilingual AI data operations
AI fails when the operational layer is weak
Models can be impressive in demos and still fail in production. The usual causes are not mysterious: incomplete training coverage, poor metadata, missing alignment signals, weak evaluation methodology, unmanaged knowledge sources, and no reliable human feedback loop after deployment.
Collect
Gather the right multilingual, domain-specific, and policy-relevant data instead of relying on generic sources.
Structure
Define metadata, labels, formats, and instructions so the data becomes usable for model training, retrieval, and review.

Align
Capture human judgments, preferences, risk signals, and enterprise expectations through RLHF and related workflows.
Evaluate
Test outputs with gold standards, multilingual reviewers, factuality checks, and recurring benchmark processes.
Govern
Control privacy, handling rules, auditability, and deployment discipline, so AI becomes trustworthy at enterprise scale.

Representative Use Cases
How organizations can use Pangeanic’s AI data operations
These examples are intentionally broad so the hub page speaks to buyers across AI labs, enterprise innovation teams, platform groups, and multilingual content environments.
Enterprise copilots
Prepare instruction data, define policy rules, and evaluate responses for internal assistants used in customer support, operations, procurement, legal intake, or employee knowledge access.
RAG systems for global content
Curate multilingual content repositories, structure metadata, improve retrieval quality, and evaluate grounded responses across languages, business units, and markets.
Domain-adapted LLMs
Build training and fine-tuning pipelines for specialist AI systems in finance, healthcare, public sector, legal, life sciences, industry, and other quality-sensitive environments.
Human review at scale
Introduce multilingual reviewers, quality protocols, and structured scoring frameworks to monitor AI output performance beyond automated benchmarks alone.
Responsible AI deployment
Integrate privacy-aware data preparation, documentation, traceability, and policy-driven review into the operational lifecycle of enterprise AI systems.
Global model expansion
Extend AI systems into new markets and languages with locale-sensitive data, terminology-aware workflows, and multilingual alignment rather than simple translation alone.
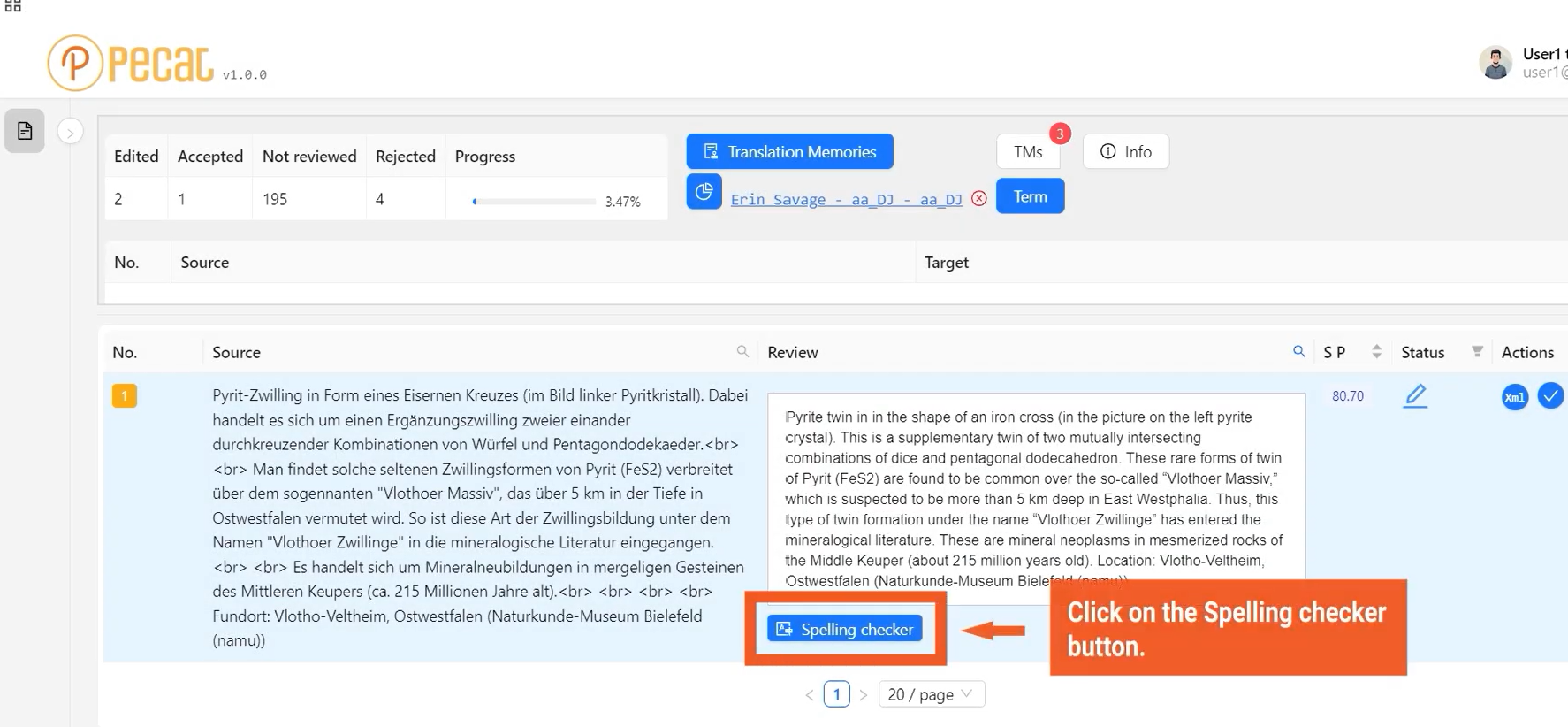
Featured in the Gartner® Hype Cycle™ for Natural Language Technologies (2023, 2024), Vendor in Conversational AI (December 2024), and Synthetic Data & Data Masking (July 2024)
Gartner’s analysis of risks and opportunities in language technology adoption highlights Pangeanic’s leadership in the field:
- Sample Vendor Recognition: Pangeanic is recognized as a Sample Vendor for Neural Machine Translation (NMT) in the 2023 and 2024 Hype Cycle reports.
- Advanced Customization: The report highlights our specialized capability to adapt and fine-tune linguistic models to the unique, high-precision needs of our clients, from Farsi machine translation for OSInt to Arabic to Russian machine translation, and to specific models with slang and drug cartel jargon.
- Strategic Foundation for SLMs: Our government- and industry-validated expertise in Neural Machine Translation customization serves as the technical cornerstone for our larger specialized Small Language Model (SLM) development.
- Representative Vendor in Gartner's Emerging Tech: Conversational AI.
.png)









Frequently Asked Questions About AI Data Operations
What are AI data operations?
AI data operations are the structured processes that prepare, align, evaluate, and govern the data used to train and operate AI systems. These workflows include multilingual training datasets, human feedback pipelines such as RLHF, evaluation frameworks, RAG knowledge grounding, and governance controls. Without these operational layers, even powerful AI models struggle to perform reliably in production environments.
Why are AI data operations critical for enterprise AI?
Large language models alone do not guarantee reliable results. Enterprises require high-quality training data, domain adaptation, human evaluation, and governance frameworks to ensure models behave consistently and safely. AI data operations create the feedback loops and quality controls that transform experimental models into dependable production systems.
How are AI data operations different from simple data labeling?
Data labeling is only one component of the AI lifecycle. AI data operations include dataset curation, annotation, instruction tuning, RLHF preference data, model evaluation, governance controls, and multilingual scaling. The objective is not simply labeled data but a continuous human-in-the-loop infrastructure supporting AI development and deployment.
What role does RLHF play in enterprise AI systems?
Reinforcement Learning from Human Feedback (RLHF) allows models to learn which responses humans prefer. Through structured preference ranking, safety labeling, and evaluation signals, organizations can align AI outputs with internal policies, domain expertise, and user expectations.
How are LLMs and AI agents evaluated in production systems?
Evaluation combines human scoring, benchmark datasets, and task-specific test sets. These frameworks measure factual accuracy, groundedness, clarity, task completion, and safety across languages and domains. Continuous evaluation allows AI teams to monitor model performance as systems evolve.
What is knowledge grounding in RAG systems?
Retrieval-augmented generation systems rely on curated knowledge sources rather than relying solely on model memory. Knowledge grounding involves preparing documents, structuring semantic chunks, defining metadata, and optimizing retrieval pipelines so AI systems generate answers based on verifiable enterprise knowledge.
How does Pangeanic support multilingual AI systems?
Many AI pipelines remain optimized for English. Pangeanic provides multilingual expertise in training data preparation, RLHF pipelines, evaluation frameworks, and knowledge grounding. This enables AI systems to perform reliably across languages, regions, and cultural contexts.
How do you address privacy and compliance in AI data pipelines?
Enterprise AI systems must comply with strict privacy and regulatory requirements. Pangeanic integrates anonymization workflows, secure data preparation, governance-aware processes, and data minimization strategies so training and evaluation datasets protect sensitive information while remaining usable for AI development.
What types of organizations benefit from AI data operations?
Technology companies developing LLMs, enterprises deploying internal copilots, research institutions building domain models, and organizations implementing RAG or agentic systems all require structured AI data operations. These workflows ensure AI remains accurate, safe, and aligned with organizational knowledge.
How quickly can AI data operations pipelines be implemented?
Initial evaluation frameworks and data preparation pipelines can typically be implemented within a few weeks, depending on project scope and available data. Over time these evolve into continuous feedback loops supporting model retraining, evaluation, and improvement.
Technical Questions About AI Data Operations
What datasets are required for RLHF?
RLHF pipelines typically require several dataset types: instruction–response pairs for supervised fine-tuning (SFT), preference ranking datasets where reviewers compare multiple outputs, and safety datasets labeling harmful or policy-violating content. These datasets train reward models that guide reinforcement learning and improve model alignment.
What is the difference between supervised fine-tuning (SFT) and RLHF?
SFT trains models using curated examples of desired outputs. RLHF adds a second layer where humans rank outputs and provide preference signals. SFT establishes baseline capability, while RLHF refines usefulness, safety, and behavioral alignment.
How are hallucinations detected in LLM evaluation?
Hallucination detection combines human evaluation with grounded benchmark datasets. Reviewers assess whether responses can be verified against trusted sources while automated metrics measure factual consistency and citation accuracy across prompts and domains.
How are multilingual evaluation benchmarks designed?
Multilingual benchmarks require balanced datasets across languages, consistent scoring frameworks, and native-language reviewers. Evaluation must account for linguistic variation, cultural context, and domain terminology to prevent bias toward high-resource languages.
What role does metadata play in AI training datasets?
Metadata provides structured context about language, domain, speaker attributes, document source, and environment. This allows AI teams to filter data efficiently, build balanced training splits, and analyze model performance under different conditions.
How are datasets prepared for retrieval-augmented generation (RAG)?
Preparing RAG datasets involves document normalization, semantic chunking, metadata definition, and indexing strategies that optimize retrieval accuracy. Proper preparation ensures that AI systems generate responses grounded in verifiable sources.
How large does a training dataset need to be?
Dataset quality and relevance are often more important than size. High-quality domain-specific datasets frequently outperform massive generic corpora when training AI models for specialized enterprise tasks.
How do human reviewers improve AI models?
Human reviewers provide qualitative signals that automated metrics cannot capture, such as clarity, usefulness, tone, and compliance with policy guidelines. These signals feed alignment datasets and evaluation pipelines that help models improve over time.
Can AI data operations support AI agents and autonomous systems?
Yes. AI agents require structured evaluation pipelines, alignment datasets, and grounded knowledge sources to perform reliably. Human-in-the-loop feedback helps ensure agents execute tasks safely and accurately in real-world environments.
How do AI teams maintain quality as models evolve?
Continuous evaluation pipelines track performance across benchmarks and real-world tasks. Regression testing, updated datasets, and periodic human review ensure that model improvements do not introduce unintended errors or safety risks.

Talk to Pangeanic
Need a partner for training data, alignment, evaluation, or multilingual AI readiness?
Whether you are building an enterprise copilot, expanding a language model into new markets, improving RAG quality, or creating a governance-aware human feedback layer, Pangeanic can help design and operate the data workflows behind reliable AI.

 .
.