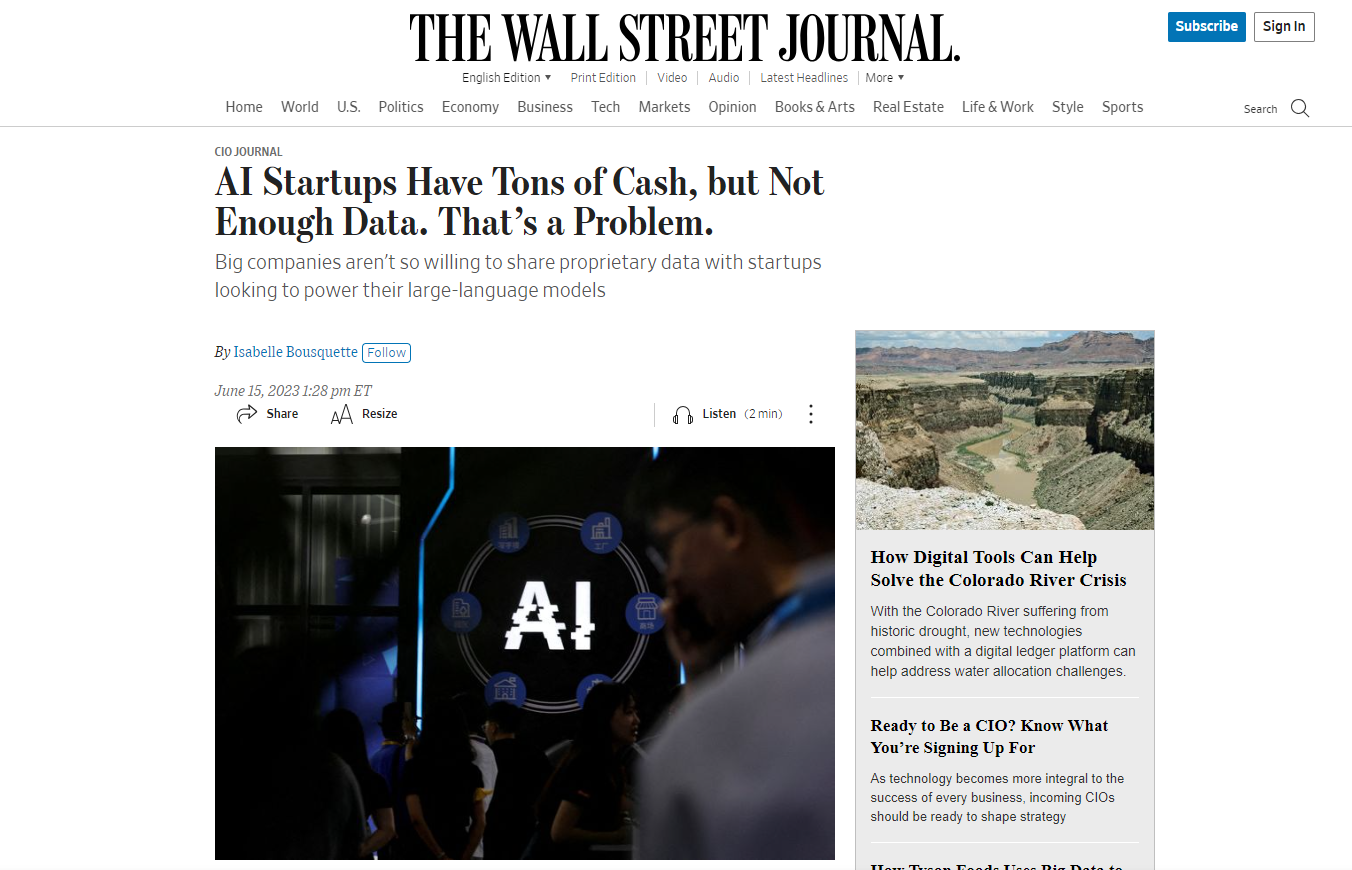
AIのトレーニング用データ
最適なAIトレーニングデータセットで機械学習を促進する
Pangeanicの商用データセットを使用して、よりスマートなAIをトレーニングします。
企業やスタートアップは、システムの精度を向上させるために、AIのトレーニングデータセットや人間からのフィードバックを用いた強化学習(RLHF)の信頼できるソースを求めています。Pangeanicは、AIのための高品質のトレーニングデータセットを提供し、世界最高のAIシステムの進歩に貢献してきました。

Gartner Hype Cycle for NLP Technologies - Neural Machine Translationに掲載
ガートナー社が最近発表した言語テクノロジー導入のリスクと機会に関する分析では、特に当社のニューロン機械翻訳(NMT)について言及し、顧客の要求に応じてNMTモデルを調整して適応させる、当社の能力を高く評価しています。

データ入手により成功を実現したいジェネレーティブAI企業ですか?
今日のデータ主導の世界では、大企業が競争力を持っています。Pangeanicでは、高品質データが重要であることを認識しています。お客様のデータアクセスの課題を克服し、パートナーシップを確立し、機密情報を保護するためのお手伝いをいたします。データ不足に悩まされることなく、お客様の生成AIの成功を後押しするために、今すぐ弊社にご連絡ください。

パラレルデータ(機械翻訳システムの構築に使用される対訳データセット)

アノテーションデータ(固有表現抽出)

テーマ画像

文中での肯定的または否定的な意見テキストまたは音声ラベリングとアノテーション

音声データセット、スクリプト、または音声モデルを改善するための会話...100以上の言語に対応します


MLモデルの最適化
多様な構造化データセット、画像、音声を使用してモデルのパフォーマンスを向上させます。

大規模言語モデルのトレーニングや微調整
Llama2、BERT、XLNet、T5、ELMO、RoBERTaなどのLLM用モノリンガルデータ。ウェブ上や製造現場から収集した大量のキュレーションデータセットを使って、より正確で関連性の高い結果を得ることができます。

NLPアプリケーションの強化
より優れた自然言語処理アプリケーションを構築し、微調整し、改善されたアノテーションの品質、データ表現、および言語の多様性を特徴とするデータセットを使用して、翻訳でより多くの言語をカバーします。

キーワード抽出と要約の改善
機械学習モデルに膨大なデータセットを供給し、あらゆる言語での優れたキーワードやフレーズの抽出と要約を実現します。

人間のフィードバックによる強化学習
前回の訓練の成果を判断するために、カスタムヒューマンサービスベンダーが必要ですか?Pangeanicは、人間がお客様のAIをより正確にするためのRLHFサービスを提供しています。

QAと情報検索のモデルをテスト・訓練
あらゆる言語の膨大で高品質なデータセットを使用して、質問応答モデルを改善します。データ収集およびデータ作成サービスを提供しています。より高い関連性が得られます。
必要な言語でカスタマイズされたデータ収集:NLPチームが提供するAIトレーニングおよびAIテスト用のデータセットです

Pangeanicは、100億の整列されたデータセグメントの巨大なリポジトリによって、AIのトレーニングのためのスケーラブルな大量のデータセットを提供することができます。また、AIのトレーニングに使用されるデータセット用にカスタマイズされた人間ベースのソリューションを提供することもできます。
言語サービスにおいて20年以上の経験を持ち、2009年からはNLP開発者でもあります。各プロジェクトは慎重に評価され、弊社のプロの言語スペシャリストがデータ収集を管理するためのルールセットが作成されます。PangeanicのAIトレーニング用データはすべて、拡張性があり、正確で、お客様のニーズに合わせて調整されています。

画像および動画データ
Pangeanicは、画像や動画データにタグを付けることができるので、物体認識システムの学習に利用できます。
どんな物体認識システムでも、大規模な画像データセットが必要だと考えています。弊社のエンジニアリングチームが、お客様と密接に協力して、互換性のあるアノテーションおよびラベリングデータのセグメンテーションを作成いたします。
弊社のカスタマイズされたサービスには、画像キャプチャとアノテーション(バウンディングボックス、手書き認識、多言語動画トランスクリプションなど)が含まれます。

音声データ
新しい多言語音声データを組み合わせて、肯定的、否定的、中立的な意見で分類[タグ付け]することができます。また、アノテーションサービスもご利用いただけます。
自動音声認識システムでは、様々な状況や環境で録音された大量の高品質な音声データが必要です。Pangeanicは、年齢、アクセント、言語、話者のプロフィール、主題、背景ノイズなどの特定の要件に合わせてカスタマイズされた音声データセットを提供するリソースを持っています。


AIを次のレベルに引き上げたいですか?
ぜひ、成長とシステムの拡張を支援するためのAIデータを提供できる最適なパートナーである当社にご連絡ください。当社は、データサイエンスの専門家、言語学者、開発者、および人的資源の完璧な組み合わせを持ち、プロセスに必要な高品質なデータを提供します。

.png)
機械学習と深層学習のためのパラレルテキストデータ
機械学習は人工知能の基本的な分野であり、高品質なデータが不可欠です。当社のAI向けデータサービスは、機械学習エンジンのトレーニングに適したデータセットを提供します。

機械翻訳
機械翻訳は、グローバル化した世界において重要なアプリケーションです。当社の多言語データにより、より高い精度と流暢さで機械翻訳エンジンを訓練することができます。
Pangeanicでは、Deep Adaptive機械翻訳技術を独自に開発し、より多くのコンテンツを、より迅速かつ安全に翻訳することが可能です。



生成AI
生成AIは、テキスト、画像、音楽の自動生成などのアプリケーションを含み、ますます人気が高まっています。当社の多言語データは、生成AIエンジンのトレーニングに利用され、自動生成されたコンテンツの品質を向上させることができます。
従来のAIとは異なり、生成AIは




当社のプロフェッショナルチームと共に、AIをより賢くしたいですか?
